
We want to empower you to experiment with LLM models, build your own applications, and discover untapped problem spaces. That’s why we sat down with GitHub’s Alireza Goudarzi, a senior machine learning researcher, and Albert Ziegler, a principal machine learning engineer, to discuss the emerging architecture of today’s LLMs.
In this post, we’ll cover five major steps to building your own LLM app, the emerging architecture of today’s LLM apps, and problem areas that you can start exploring today.
Five steps to building an LLM app
Building software with LLMs, or any machine learning (ML) model, is fundamentally different from building software without them. For one, rather than compiling source code into binary to run a series of commands, developers need to navigate datasets, embeddings, and parameter weights to generate consistent and accurate outputs. After all, LLM outputs are probabilistic and don’t produce the same predictable outcomes.
Let’s break down, at a high level, the steps to build an LLM app today. 👇
1. Focus on a single problem, first. The key? Find a problem that’s the right size: one that’s focused enough so you can quickly iterate and make progress, but also big enough so that the right solution will wow users.
For instance, rather than trying to address all developer problems with AI, the GitHub Copilot team initially focused on one part of the software development lifecycle: coding functions in the IDE.
2. Choose the right LLM. You’re saving costs by building an LLM app with a pre-trained model, but how do you pick the right one? Here are some factors to consider:
- Licensing. If you hope to eventually sell your LLM app, you’ll need to use a model that has an API licensed for commercial use. To get you started on your search, here’s a community-sourced list of open LLMs that are licensed for commercial use.
-
Model size. The size of LLMs can range from 7 to 175 billion parameters—and some, like Ada, are even as small as 350 million parameters. Most LLMs (at the time of writing this post) range in size from 7-13 billion parameters.
Conventional wisdom tells us that if a model has more parameters (variables that can be adjusted to improve a model’s output), the better the model is at learning new information and providing predictions. However, the improved performance of smaller models is challenging that belief. Smaller models are also usually faster and cheaper, so improvements to the quality of their predictions make them a viable contender compared to big-name models that might be out of scope for many apps.
- Model performance. Before you customize your LLM using techniques like fine-tuning and in-context learning (which we’ll cover below), evaluate how well and fast—and how consistently—the model generates your desired output. To measure model performance, you can use offline evaluations.
3. Customize the LLM. When you train an LLM, you’re building the scaffolding and neural networks to enable deep learning. When you customize a pre-trained LLM, you’re adapting the LLM to specific tasks, such as generating text around a specific topic or in a particular style. The section below will focus on techniques for the latter. To customize a pre-trained LLM to your specific needs, you can try in-context learning, reinforcement learning from human feedback (RLHF), or fine-tuning.
- In-context learning, sometimes referred to as prompt engineering by end users, is when you provide the model with specific instructions or examples at the time of inference—or the time you’re querying the model—and asking it to infer what you need and generate a contextually relevant output.
In-context learning can be done in a variety of ways, like providing examples, rephrasing your queries, and adding a sentence that states your goal at a high-level.
-
RLHF comprises a reward model for the pre-trained LLM. The reward model is trained to predict if a user will accept or reject the output from the pre-trained LLM. The learnings from the reward model are passed to the pre-trained LLM, which will adjust its outputs based on user acceptance rate.
The benefit to RLHF is that it doesn’t require supervised learning and, consequently, expands the criteria for what’s an acceptable output. With enough human feedback, the LLM can learn that if there’s an 80% probability that a user will accept an output, then it’s fine to generate. Want to try it out? Check out these resources, including codebases, for RLHF.
-
Fine-tuning is when the model’s generated output is evaluated against an intended or known output. For example, you know that the sentiment behind a statement like this is negative: “The soup is too salty.” To evaluate the LLM, you’d feed this sentence to the model and query it to label the sentiment as positive or negative. If the model labels it as positive, then you’d adjust the model’s parameters and try prompting it again to see if it can classify the sentiment as negative.
Fine-tuning can result in a highly customized LLM that excels at a specific task, but it uses supervised learning, which requires time-intensive labeling. In other words, each input sample requires an output that’s labeled with exactly the correct answer. That way, the actual output can be measured against the labeled one and adjustments can be made to the model’s parameters. The advantage of RLHF, as mentioned above, is that you don’t need an exact label.
4. Set up the app’s architecture. The different components you’ll need to set up your LLM app can be roughly grouped into three categories:
- User input which requires a UI, an LLM, and an app hosting platform.
-
Input enrichment and prompt construction tools. This includes your data source, embedding model, a vector database, prompt construction and optimization tools, and a data filter.
-
Efficient and responsible AI tooling, which includes an LLM cache, LLM content classifier or filter, and a telemetry service to evaluate the output of your LLM app.
5. Conduct online evaluations of your app. These evaluations are considered “online” because they assess the LLM’s performance during user interaction. For example, online evaluations for GitHub Copilot are measured through acceptance rate (how often a developer accepts a completion shown to them), as well as the retention rate (how often and to what extent a developer edits an accepted completion).
The emerging architecture of LLM apps
Let’s get started on architecture. We’re going to revisit our friend Dave, whose Wi-Fi went out on the day of his World Cup watch party. Fortunately, Dave was able to get his Wi-Fi running in time for the game, thanks to an LLM-powered assistant.
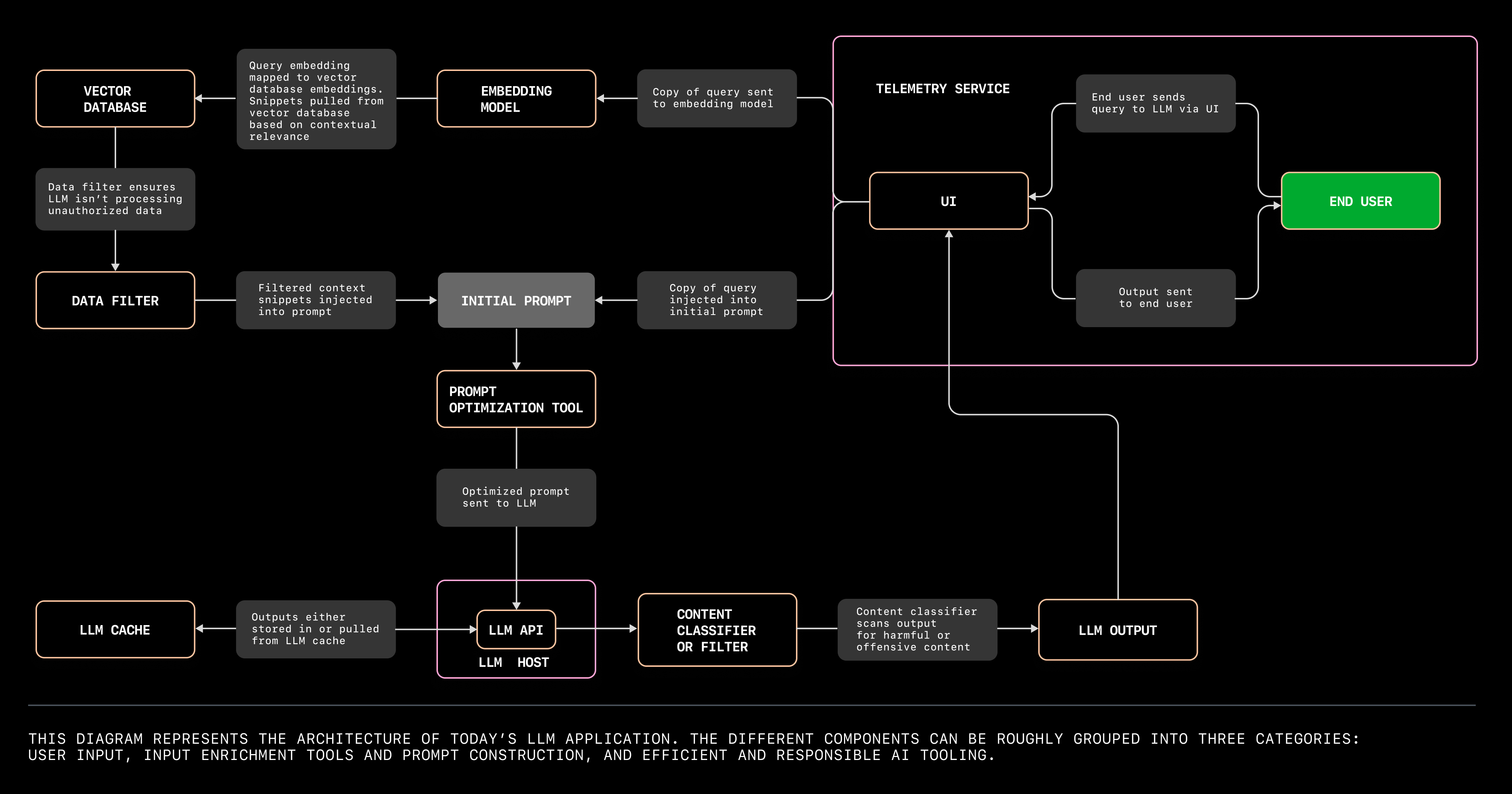
We’ll use this example and the diagram above to walk through a user flow with an LLM app, and break down the kinds of tools you’d need to build it. 👇
User input tools
When Dave’s Wi-Fi crashes, he calls his internet service provider (ISP) and is directed to an LLM-powered assistant. The assistant asks Dave to explain his emergency, and Dave responds, “My TV was connected to my Wi-Fi, but I bumped the counter, and the Wi-Fi box fell off! Now, we can’t watch the game.”
In order for Dave to interact with the LLM, we need four tools:
- LLM API and host: Is the LLM app running on a local machine or in the cloud? In an ISP’s case, it’s probably hosted in the cloud to handle the volume of calls like Dave’s. Vercel and early projects like jina-ai/rungpt aim to provide a cloud-native solution to deploy and scale LLM apps.
But if you want to build an LLM app to tinker, hosting the model on your machine might be more cost effective so that you’re not paying to spin up your cloud environment every time you want to experiment. You can find conversations on GitHub Discussions about hardware requirements for models like LLaMA‚ two of which can be found here and here.
-
The UI: Dave’s keypad is essentially the UI, but in order for Dave to use his keypad to switch from the menu of options to the emergency line, the UI needs to include a router tool.
- Speech-to-text translation tool: Dave’s verbal query then needs to be fed through a speech-to-text translation tool that works in the background.
Input enrichment and prompt construction tools
Let’s go back to Dave. The LLM can analyze the sequence of words in Dave’s transcript, classify it as an IT complaint, and provide a contextually relevant response. (The LLM’s able to do this because it’s been trained on the internet’s entire corpus, which includes IT support documentation.)
Input enrichment tools aim to contextualize and package the user’s query in a way that will generate the most useful response from the LLM.
- A vector database is where you can store embeddings, or index high-dimensional vectors. It also increases the probability that the LLM’s response is helpful by providing additional information to further contextualize your user’s query.
Let’s say the LLM assistant has access to the company’s complaints search engine, and those complaints and solutions are stored as embeddings in a vector database. Now, the LLM assistant uses information not only from the internet’s IT support documentation, but also from documentation specific to customer problems with the ISP.
-
But in order to retrieve information from the vector database that’s relevant to a user’s query, we need an embedding model to translate the query into an embedding. Because the embeddings in the vector database, as well as Dave’s query, are translated into high-dimensional vectors, the vectors will capture both the semantics and intention of the natural language, not just its syntax.
Here’s a list of open source text embedding models. OpenAI and Hugging Face also provide embedding models.
Dave’s contextualized query would then read like this:
// pay attention to the the following relevant information.
<In the event of any malfunction look at the LED panel first and pay attention
to the colors and blinking pattern.
// pay attention to the following relevant information.
<If you notice the amber square line blinking there is a physical line
connection failure. Inspect the connection to the wifi router and the wall
plate to make sure the cable is securely connected.>
// The following is an IT complaint from, Dave Anderson, IT support expert.
Answers to Dave's questions should serve as an example of the excellent support
provided by the ISP to its customers.
*Dave: Oh it's awful! This is the big game day. My TV was connected to my
Wi-Fi, but I bumped the counter and the Wi-Fi box fell off and broke! Now we
can't watch the game.
Not only do these series of prompts contextualize Dave’s issue as an IT complaint, they also pull in context from the company’s complaints search engine. That context includes common internet connectivity issues and solutions.
MongoDB released a public preview of Vector Atlas Search, which indexes high-dimensional vectors within MongoDB. Qdrant, Pinecone, and Milvus also provide free or open source vector databases.
- A data filter will ensure that the LLM isn’t processing unauthorized data, like personal identifiable information. Preliminary projects like amoffat/HeimdaLLM are working to ensure LLMs access only authorized data.
-
A prompt optimization tool will then help to package the end user’s query with all this context. In other words, the tool will help to prioritize which context embeddings are most relevant, and in which order those embeddings should be organized in order for the LLM to produce the most contextually relevant response. This step is what ML researchers call prompt engineering, where a series of algorithms create a prompt. (A note that this is different from the prompt engineering that end users do, which is also known as in-context learning).
Prompt optimization tools like langchain-ai/langchain help you to compile prompts for your end users. Otherwise, you’ll need to DIY a series of algorithms that retrieve embeddings from the vector database, grab snippets of the relevant context, and order them. If you go this latter route, you could use GitHub Copilot Chat or ChatGPT to assist you.
| Learn how the GitHub Copilot team uses the Jaccard similarity to decide which pieces of context are most relevant to a user’s query > |
Efficient and responsible AI tooling
To ensure that Dave doesn’t become even more frustrated by waiting for the LLM assistant to generate a response, the LLM can quickly retrieve an output from a cache. And in the case that Dave does have an outburst, we can use a content classifier to make sure the LLM app doesn’t respond in kind. The telemetry service will also evaluate Dave’s interaction with the UI so that you, the developer, can improve the user experience based on Dave’s behavior.
- An LLM cache stores outputs. This means instead of generating new responses to the same query (because Dave isn’t the first person whose internet has gone down), the LLM can retrieve outputs from the cache that have been used for similar queries. Caching outputs can reduce latency, computational costs, and variability in suggestions.
You can experiment with a tool like zilliztech/GPTcache to cache your app’s responses.
-
A content classifier or filter can prevent your automated assistant from responding with harmful or offensive suggestions (in the case that your end users take their frustration out on your LLM app).
Tools like derwiki/llm-prompt-injection-filtering and laiyer-ai/llm-guard are in their early stages but working toward preventing this problem.
-
A telemetry service will allow you to evaluate how well your app is working with actual users. A service that responsibly and transparently monitors user activity (like how often they accept or change a suggestion) can share useful data to help improve your app and make it more useful.
OpenTelemetry, for example, is an open source framework that gives developers a standardized way to collect, process, and export telemetry data across development, testing, staging, and production environments.
Learn how GitHub uses OpenTelemetry to measure Git performance >
Woohoo! 🥳 Your LLM assistant has effectively answered Dave’s many queries. His router is up and working, and he’s ready for his World Cup watch party. Mission accomplished!
Real-world impact of LLMs
Looking for inspiration or a problem space to start exploring? Here’s a list of ongoing projects where LLM apps and models are making real-world impact.
- NASA and IBM recently open sourced the largest geospatial AI model to increase access to NASA earth science data. The hope is to accelerate discovery and understanding of climate effects.
- Read how the Johns Hopkins Applied Physics Laboratory is designing a conversational AI agent that provides, in plain English, medical guidance to untrained soldiers in the field based on established care procedures.
- Companies like Duolingo and Mercado Libre are using GitHub Copilot to help more people learn another language (for free) and democratize ecommerce in Latin America, respectively.






