
Ever wondered how the largest open source platform manages its vulnerabilities? GitHub’s security team built an agile vulnerability management program, capable of protecting a growing population of over 100 million developers—and their data—around the world. For GitHub’s security team, vulnerability management goes well beyond patch management. It’s an intelligence function that enables the security team to assess potential exposure to threats and provides a likelihood of exploitation. GitHub’s approach to vulnerability management focuses on speeding up time to understanding the material impact on the business if a vulnerability were to be exploited. Treating vulnerability management as an intelligence function empowers GitHub’s security leaders to make rapid, informed decisions on actions in order to mitigate risk.
Let’s dive in.
Our challenges
Like many global organizations, GitHub has a substantial infrastructure footprint that stretches across numerous cloud providers and data centers worldwide. With this scale, our infrastructure comes in many flavors and with individual risk profiles that we need to continuously evaluate. To help assess, evaluate, and secure this, we have a diverse security team collaborating across the globe, with each team member bringing their own skills and subject matter expertise to apply.
However, like many teams, we previously relied on many bespoke processes to do this. Let’s take, for example, when a security team member found a new application vulnerability that needed to be documented, reviewed, and tracked throughout its lifecycle. That team member would leverage the bespoke processes of their group within our larger security organization to do so. As you can imagine, this led to a few different challenges:
- Operational overhead: we were investing a significant amount of resources in creating redundant tools and processes. This created not only a growing operational burden but also required our security teams to often context switch between their regular daily tasks and maintaining or developing automated solutions for managing findings.
- Inconsistent user experience: our developer experiences varied depending on which security team created a finding. For example, in certain instances, findings were automatically updated, while others necessitated a chatop intervention or some required more hands-on action. This variation led to confusion among service owners and engineers.
Combined, these impacts made it hard to measure and scale our programs automatically and increased the likelihood of human error.
Defining our requirements
In building our application security solutions like GitHub Advanced Security (GHAS), we have developed many best practices around changing the experience of security by deeply understanding the environment and workflow and prioritizing the user experience. We knew we needed to apply this same approach to our vulnerability management program, including:
- Automation: to help our teams automate all repeatable steps, reduce context switching and operational overhead, and avoid human error or delays.
- Broad intelligence ingestion: as an integral part of our security practices, we leverage GHAS extensively to help us improve and maintain the quality of our code. In addition to GHAS, we also run internal security processes, such as our Bug Bounty program, or even third-party tools, such as cloud security posture management solutions and container scanners. We know the landscape of security is continuously changing, so it is imperative we can adapt along with it.
- Just-in-time context: to help teams move beyond patch management to having curated intelligence to take better action. This involves providing context like a confidence level regarding the likelihood of exploitation and the potential material impact on our business if a vulnerability were to be exploited.
- Clear ownership: clear accountability and responsibility to help drive next steps and action.
- On-demand analytics: to drive informed decisions that can be made on which actions to undertake to mitigate risks.
Deploying a solution
After extensive research, we moved forward with our own custom-built tool, Security Findings. Security Findings ingests and normalizes data from multiple sources, creates actionable findings, and manages the lifecycle of those findings.

Consolidating all our data in one central location offers a multitude of benefits that were previously beyond our reach, for example:
- Reduced noise: the market offers a wide array of tools, each possessing unique detection capabilities. However, the overlap across these solutions can be challenging. It is crucial for teams to avoid receiving duplicative findings, and Security Findings can deduplicate the data to ensure we get the best of both worlds.
- Solution agility: when a security vendor becomes deprecated or requires replacement, the transition effort is minimal for the security team and there is little-to-no-impact to engineering teams. This means we maintain the agility to swiftly embrace other vendor options as they become available.
- Single source of truth: wWe possess a singular solution for reviewing open security findings pertaining to our services, regardless of their source.
- Enhanced intelligence: we can leverage data mining techniques on this information to gain deeper insights into areas where we require increased investments to address technical debt, as well as identify strategic areas to implement safeguards that yield the most favorable return on investment.
Delivering a intuitive user experience
We committed to crafting a user experience that effectively conveys vast amounts of data in the most intuitive manner possible–this means cutting down the noise and providing information in context. To do this, internal users have the ability to access information through a wide variety of views and can filter them to their needs. For example, an engineer might choose to perform an in-depth analysis of a particular security finding, while a manager may prefer a high-level overview of their organization’s overall status.
Furthermore, Security Findings is equipped with role-based access controls to ensure that individuals can only access security findings related to the services they are responsible for. In addition, it empowers us to adhere to established frameworks like the Traffic Light Protocol (TLP) and accommodate sensitive TLP:Red findings, which typically limit access to a very select group of individuals. This level of control is of paramount importance, given the sensitive nature of the information stored.
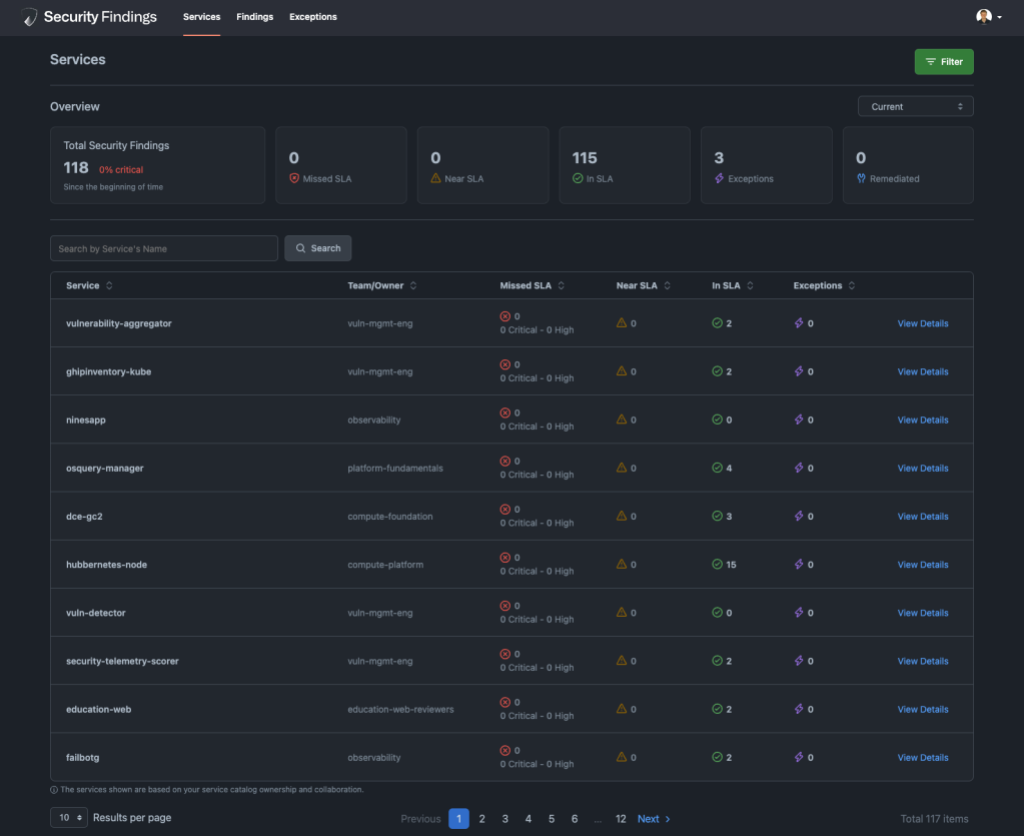
We found that to provide the best user experience it is valuable for us to provide a dynamic UI capable of adapting to various deployment methods we employ. For instance, when dealing with containerized applications, engineers will benefit from information on vulnerable images and their deployment locations. In contrast, for a virtual machine in a data center, they would prefer details like IP addresses and hostnames. We have a wide range of views tailored to all the supported scenarios we’ve run into and this framework is readily expandable.
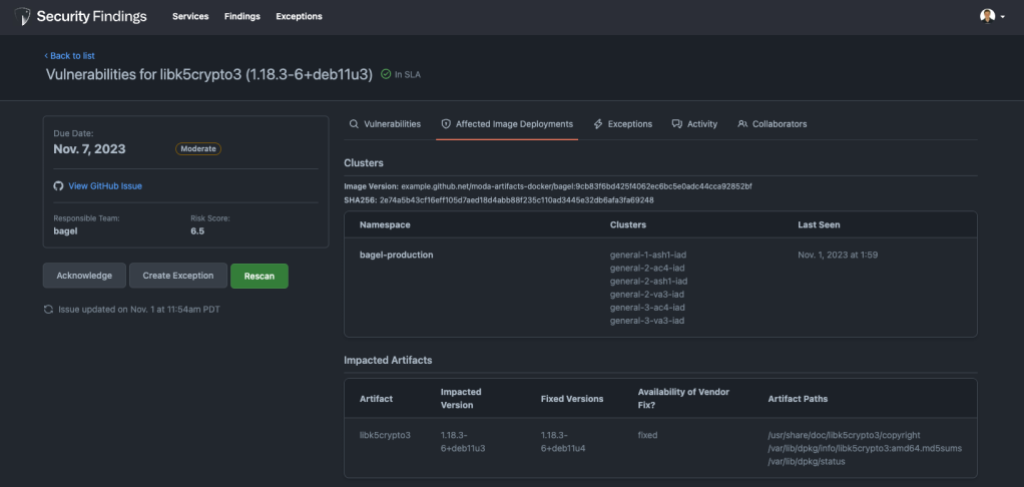
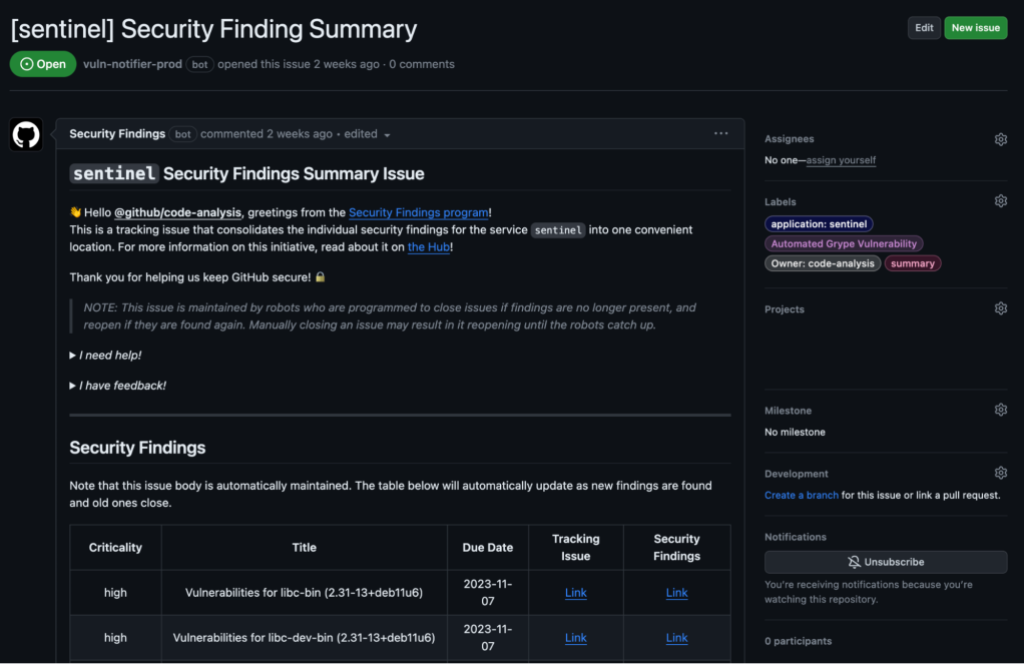
Security should never be an afterthought, and a core principle that drives our solutions is to bring security to where developers work. Therefore, we decided to embed Security Findings into our developer workflow alongside our use of GitHub. As the home for all developers, GitHub already provides us with a feature rich platform. For example, GitHub Issues allow us to @mention the appropriate teams and they can use features such as GitHub notifications and projects to manage remediation activities alongside all their other work. GitHub also features CI results in which we can show live scan results without an engineer ever needing to context switch into another tool. This approach significantly streamlines the tracking of security remediation activities, providing a level of convenience and familiarity that leverages the broader ecosystem that our teams are already proficient in.
Handling security exceptions
As we continued to grow the number of findings flowing through Security Findings we found it increasingly difficult to deal with security exceptions. They come up for a variety of reasons. Some examples are false positives, remediation extensions, and risk acceptances. Our initial approach was to store them in YAML files but we found that difficult to scale as it alienated individuals who were not comfortable with YAML files and made it difficult to conduct reporting and lifecycle management. To combat this, we decided to fold our security exceptions program into Security Findings so that users have a single end-to-end experience.
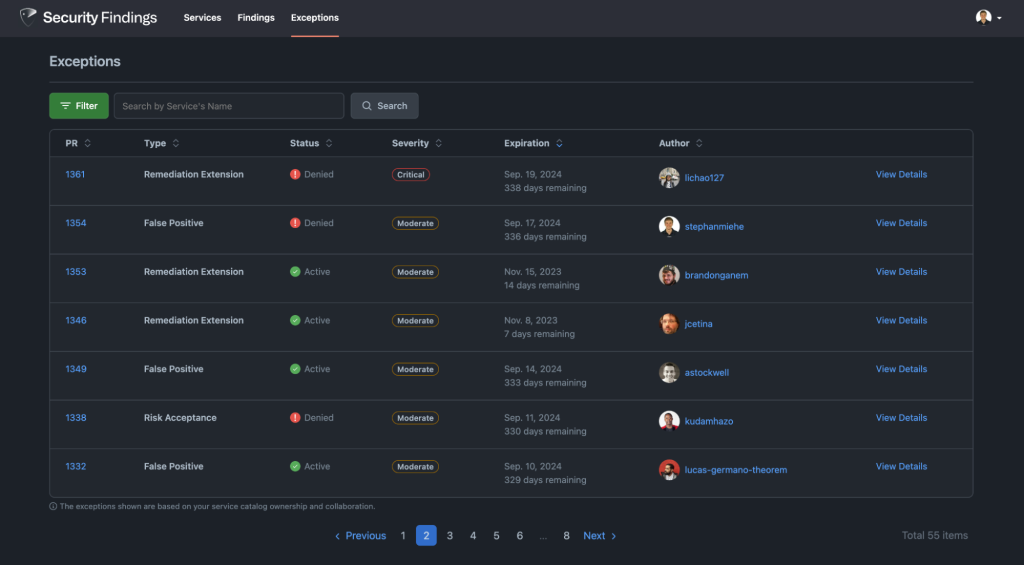
Similarly to findings, users have a convenient means of accessing a comprehensive list of exceptions associated with the services under their purview. This feature proves invaluable, particularly in scenarios involving the inheritance of services when an employee joins or takes on a new scope, as it enables a quick assessment of the security posture of the services being assumed. Furthermore, this information aids teams in seamlessly integrating technical security debt considerations into their planning efforts, especially when tackling remediations that may require substantial architectural modifications. In particular for remediation extensions, it’s important to track remediation efforts that have a long timeline. To help with this we collect monthly milestones while the exception is valid. Service owners each month indicate if they’re on track or off track creating an active conversation and shared sense of ownership.
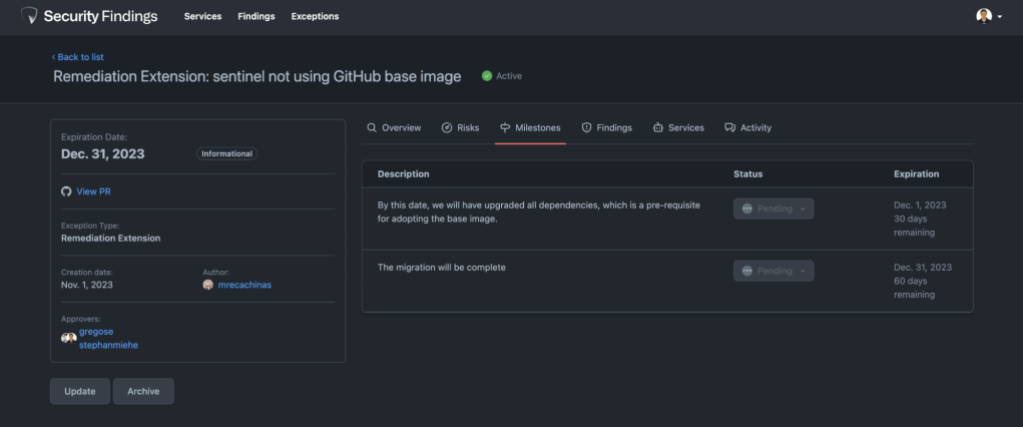
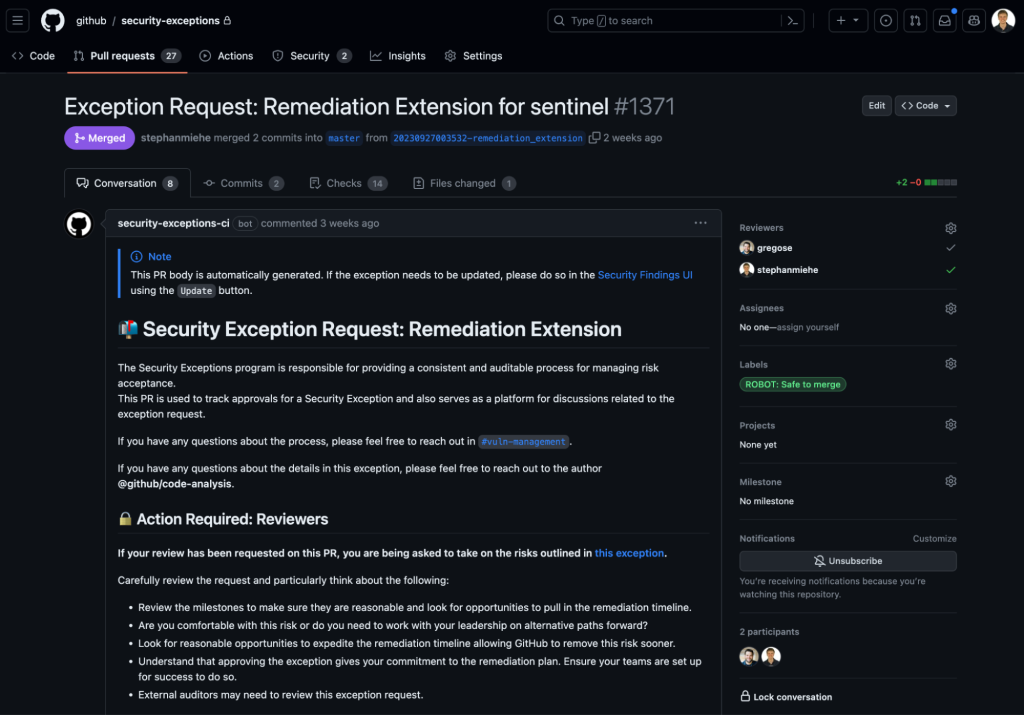
Earlier on we mentioned our extensive use of GitHub to run GitHub.com. We decided to leverage pull requests to capture approvals for security exceptions. The list of approvals required for a security exception are calculated based on a wide variety of factors, such as the type and risk of an exception. This ensures the right individuals are aware of the risk the business is taking on. Just like GitHub Issues, our internal users are already acquainted with pull requests, which ensures a familiar and user-friendly experience.
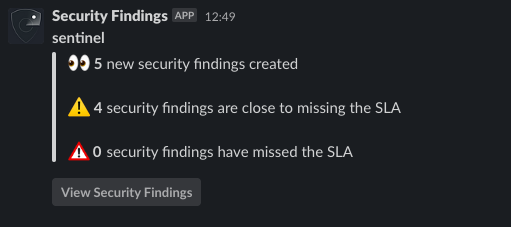
Sometimes we need more real time alerts for Security Findings, both for reminders or critical mitigation. We integrated Slack into Security Findings to accomplish this. Whether it’s communicating the current state of findings or reminding service owners about upcoming security exception milestones, it’s only a simple Slack message away.
Conclusion
We invest substantial effort to ensure the comprehensive scanning of components across our infrastructure. This includes scanning images, virtual machines, cloud resources, and other assets to guarantee that they remain within our surveillance. This proactive approach allows us to swiftly address any newly identified risks with confidence. Since the introduction of our Security Findings initiative within GitHub last year, we’ve processed over 150 million findings. Every discovery undergoes automated analysis as part of our pipeline, and if necessary, it receives manual triage. This process not only enriches the data but also assesses its relevance and, if necessary, directs it for appropriate action.
By sticking to our core principles of making security easy to consume we’ve witnessed a transformation in our ability to manage and expand our security findings handling across the organization. This enables our security teams to concentrate on the most critical aspects of their work and developers to gain time back to focus on building new features.
We hope that by sharing our learnings and the best practices we’ve discovered we can continue to fuel growth in security mindsets and collective knowledge sharing to help us all secure the world together.
Ready to embark on a journey with us? Explore our careers page for thrilling opportunities and join the adventure!




