
GitHub’s primary codebase is a large Ruby on Rails monolith with over 4.2 million lines of code across roughly 30,000 files. As the platform has grown over the years, we have come to realize that we need a new way to organize and think about the systems we run. Our traditional approach to organizing Hubbers and code has been through CODEOWNERS in combination with GitHub teams, organizations, issues, and repositories. However, as GitHub’s user base continues to grow, we have discovered we need a new layer of abstraction. This is where SERVICEOWNERS comes in.
Service-oriented architecture is not new, but we do not talk often about how large engineering teams organize around services–especially in a hybrid monolith/services architecture. GitHub engineering determined that we were missing a layer in between CODEOWNERS, how we group humans, and work to be done. Injecting a “service” layer between groups of functionality and the people maintaining them opens up a number of interesting possibilities.
One side-effect of adopting SERVICEOWNERS was realizing that the “ownership” model does not quite express how we work. Given our place in the open source ecosystem and what we value as a company, we thought the “maintainer” model more accurately describes the relationships between services and teams. So, no team “owns” anything, but instead they “maintain” various services.
Consistent, company-wide grouping
Achieving consistency in how we map running code–both within and without our monolith–to humans has had a number of positive outcomes. It promotes a shared lexicon, and, therefore, a shared understanding. The durability of services reduces the disruption of team reorganization. As priorities shift, services stay the same and require only minimal updates to yaml metadata to be accurate. Consistency in our service definitions also allows us to centralize information about the services we run into a service catalog. Our service catalog is the one-stop shop for up-to-date information on the services that power GitHub. Within the catalog, Hubbers of all stripes can find information on, for example, how a service is performing vis-a-vis an SLO. Each service in the service catalog also has a number of scorecards as part of our fundamentals program.
With clearly defined services collected in a service catalog, we can easily visualize the relationships between services. We can identify dependencies and map how information flows through the platform. All this information improves the onboarding experience for new engineers, too, as the relationships between services define the platform architecture—without having to rely on out-of-date docs or hand-waving to explain our architecture.
The service catalog also has the huge benefit of centralizing information about which teams maintain which services, how to reach an on-call engineer, and what expectations the service has set in terms of support SLAs. Clean lines of communication to maintainers of running services has been a huge help in reducing our incident remediation time. Incident commanders know how to contact on-call engineers because they can find it in the service catalog. All of this is only possible thanks to SERVICEOWNERS.
How it works
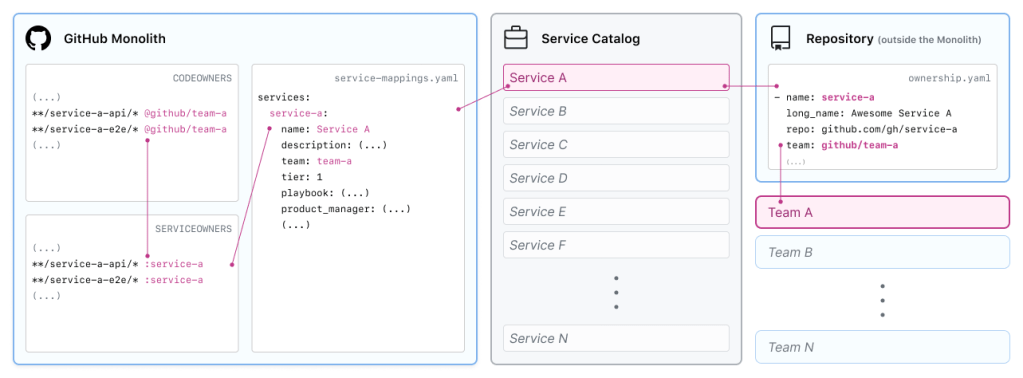
The SERVICEOWNERS file
A SERVICEOWNERS file lives next to the CODEOWNERS file within our monolith. Like a traditional CODEOWNERS file, SERVICEOWNERS consists of a series of glob patterns (for example, app/api/integration*), directory names (for example, config/access_control/) and filenames (for example, app/api/grants.rb) followed by a service name (for example :apps maps to the team github/apps). Our CI enforces rules like:
- There can be no duplicate patterns/directories/files in
SERVICEOWNERS. - All new files added to the github/github repository must have a service owner.
- All patterns/directories/files must match at least one existing file.
- Files matched by multiple glob patterns must be disambiguated by a file or directory definition.
The service-mappings.yaml file
A service-mappings file defines how services referenced in the SERVICEOWNERS file relate to services in the service catalog and GitHub teams. This configuration can define a service’s product manager, engineering manager, repository, and chat information. Service mappings can also define information about a service’s various classifications, such as its “tier” rating, with zero being critical to the GitHub platform and three being experimental/non-critical.
The serviceowners gem
We have developed a Ruby gem we integrate with our Rails app that combines data from the SERVICEOWNERS and service-mappings files to produce several types of output. The serviceowners gem generates our CODEOWNERS file. So, instead of manually updating CODEOWNERSchanging which team or teams maintain a service is a one-line YAML change. The serviceowners gem also has an executable which allows engineers to query information about the maintainer of a file or which files a service maintains.
Because it’s GitHub, there’s of course also a chat-op for that:
me: hubot serviceowners for test/jobs/do_the_thing_with_the_stuff_test.rb
naked: The file
test/jobs/do_the_thing_with_the_stuff_test.rbis part of thegithub/some_service serviceand is maintained by thecool-fun-teamteam who can be reached in #hijinx.
The ownership.yaml file
The above examples mostly focus on breaking up the monolith into services, but our service catalog can slurp up service information from any repository within the GitHub org that has an ownership.yaml file. Like the service-mappings file, ownership expresses version controlled values for various service metadata. This allows us to have the boundaries of a service span across multiple repositories; for example, the GitHub Desktop app can have a component service within the monolith while also having its own standalone artifact from a different repository. Another benefit of the ownership file is that it allows us to focus code changes to the monolith codebase primarily around functionality and not maintainership.
Conclusion
The combination of CODEOWNERS and SERVICEOWNERS has provided serious value for us at GitHub. The tooling we continue to build atop these primitives will serve to make maintaining services clearer and easier. That’s good news for the future of GitHub. It also pairs quite nicely with our open source identity and access management project, entitlements, too. If SERVICEOWNERS sounds like something your organization, open source or corporate alike, would benefit from, let us know on X at @github.






